Web Scraping

Web Scraping
El Web Scraping es una técnica utilizada mediante programas de software para extraer información de sitios web de forma automatizada.
Nos veremos enfrentados a diversos casos cuando queramos utilizar esta técnica, las diferencias son los siguientes:
Entender que tipo de página web es la que queremos extraer la información, si esta es una página
Web Estática, le agradecemos a Dios porque es la mas simple de poder extraer información puesto que el código esta disponible de inmediato con un simple inspeccionar elementos. Para ver un ejemplo amigable de un caso real véase GITHUBPágina Dinámica, los sitios dinámicos son aquellos con los cuales se necesita interactuar con el para poder acceder a la información, ya sea apretar un botón, seleccionar una fecha especifica o otras medidas de seguridad anti robots. En esta caso vamos resolver este problemas mas complejo y a su ves mas interesante.
Para poder acceder a las páginas con mayor seguridad de información tenemos que inspeccionar elementos, luego ir a Network para entender como funciona. Usaremos de ejemplo la web Flixbus
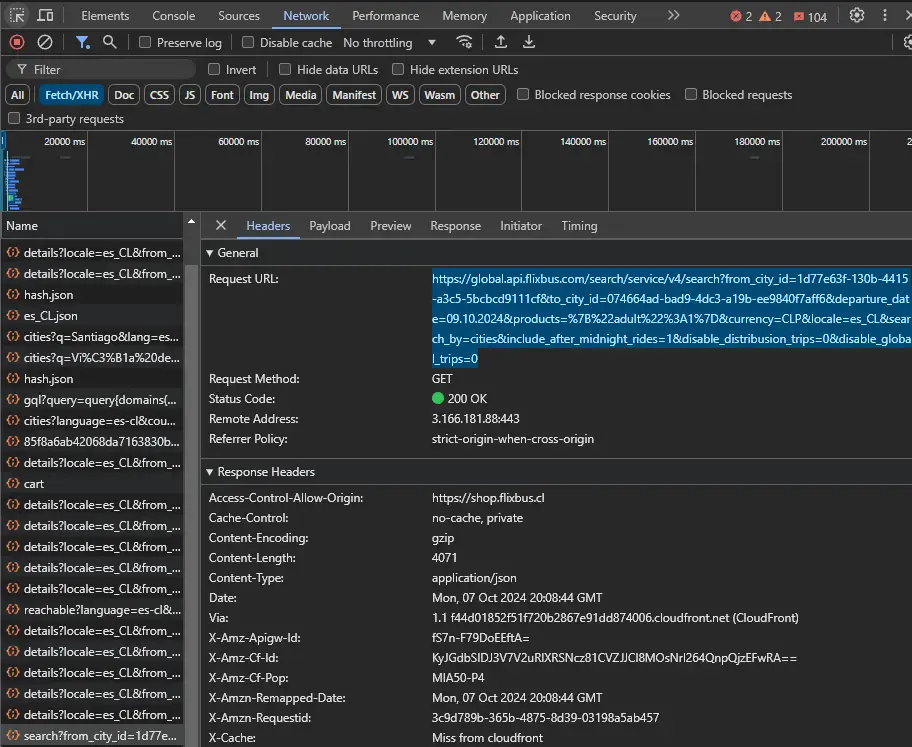
Seleccionamos la opción Fetch/XHR para poder acceder a la información del json pero para nuestro caso es un falso json porque el archivo en sí se encuentra mal preparado por lo que no podemos simplemente leer el sus Keys y obtener la información a partir de las etiquetas.
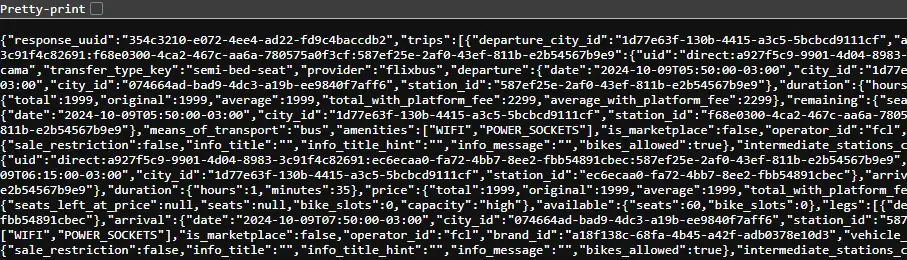
Al entrar podemos observar que el código es una sopa de caracteres, para comprender mejor como se organiza es obligatorio utilizar la opción de Pretty-Print
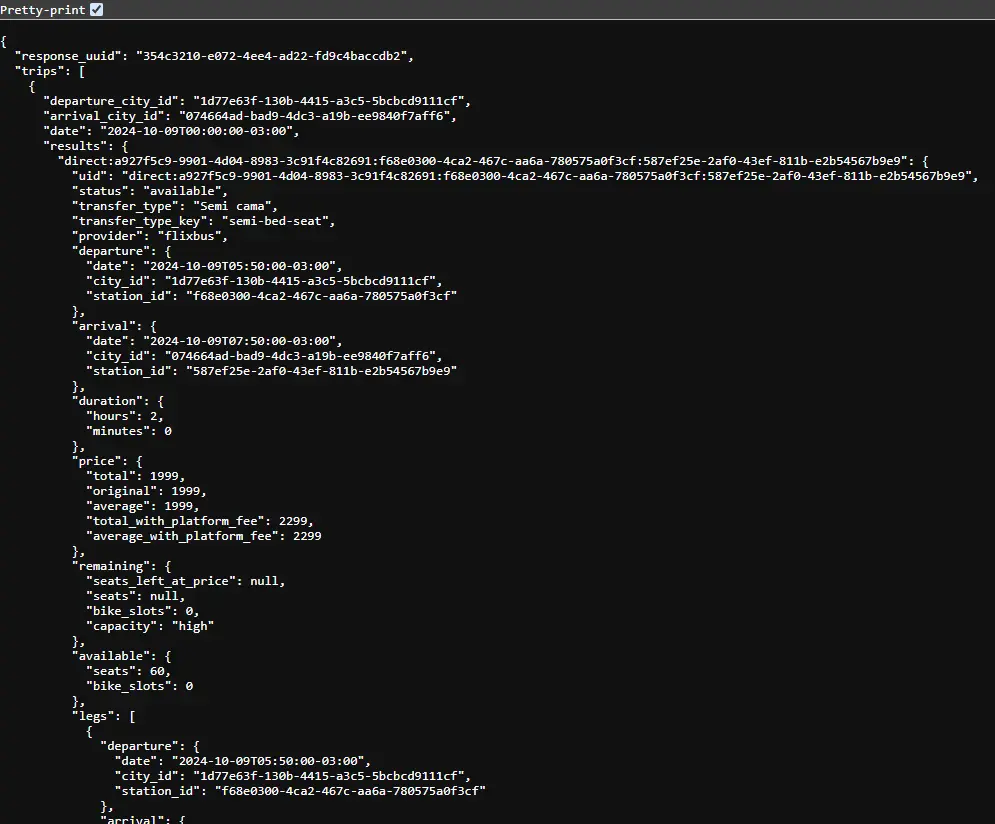
Vemos que si tiene una estructura, y como científico de datos debemos saber como manipular este código a nuestro favor. Para evitar tener un posible bloque de IP por extracción continua del sitio recomiendo descargar directamente el código y de este modo poder manipularlo sin restricciones.
Nuestra misión es poder extraer los datos del precio y la fecha de partida del bus para generar un dataframe con el cual podemos trabajar a futuro. Mi herramienta favorita para trabajar estos tipo de aventuras es Python
Para nuestro bloque de texto sabemos con anterioridad que son 64 viajes, que corresponden al día 7 de octubre del 2024. Entonces en teoría nuestro largo de información es de 64 elementos y que las fechas no pueden salir de este día.
Manos a la obra…
Primero debemos leer el archivo con with open() y guardarlo como content en nuestro caso, y nos entrega un string de 106325 caracteres
Siguiente paso será encontrar la palabra que nos indique las fechas y los precios, para eso creamos una función que busque dentro del largo de todo el string nos muestre los índices donde se encuentra la posición de estos datos. Como vemos en la imagen superior existe date para encontrar una fecha y price para encontrar los valores del pasaje.
Corremos nuestra función y observamos que tenemos 129 posibles para el precio. Entonces tenemos un problema, pero observando con un simple:
1
2
print(test[int(indices[0])]: test[int(indices[0]) + 116])
print(test[int(indices[1])]: test[int(indices[1]) + 116])
Observamos que su segundo valor corresponde a un precio que no nos entrega la información que queremos, es decir que solo los valores que no son múltiplos de 2 son los que realmente queremos.
Si se preguntan porque existe un valor de 116 que se suma, es porque corresponde a la distancia constante entre la palabra precio y los valores que queremos price" {"total": 1999,"original": 1999,"average": 1999,"total_with_platform_fee": 2299,"average_with_platform_fee": 2299}, Si bien no se ve muy atractivo todo a su tiempo querido lector.
Entonces finalmente tenemos 65 valores, pero el ultimo tampoco nos sirve es por eso que los eliminamos y nos queda con los 64 posibles viajes.
Muy bien, ahora ver como se relacionan con las fechas, corremos nuestra función y observamos que tenemos 261 posibles casos ¿Por qué a ocurrido esto?
En simple, existen 4 posibles fechas por cada viaje por lo que debiese existir 256 posibles casos mas una fecha que se encuentra antes y después de las sopa de letras que nos interesa realmente.
Entonces tenemos la suerte que al igual que anteriormente los valores que son múltiplos de 2 son los que son de importancia, lo corremos 2 veces y voila.
Tenemos el texto que realmente queremos
1
print(test[int(indices[0])]: test[int(indices[0]) + 30])
Corresponde nuestras fechas deseadas con una constante de distancia de 30 caracteres.
Creamos otra función que haga un subset para obtener la información mas limpia llamada save_values al igual que otra función que borra el carácter que nosotros indicamos llamado borrar. Finalmente tenemos que crear nuestro dataframe con los valores que obtuvimos de values_price y values_date como columna precio y fecha correspondiente, a la cual extraemos como un csv para poder analizar como se quiera.
Finalmente si usamos el código para otro día también nos entrega los resultados coherentes, es decir, generamos un web scraping con vida útil para este sitio web.
En síntesis, observamos un caso real de Web Scraping para un sitio dinámico, sus posibles dificultades y como afrontarlas. Espero que este caso complejo pueda ayudar a tu camino querido lector puesto fue un desafío del mundo real.