Web Scraping HTML

Como vimos anteriormente el Web Scraping es una técnica utilizada para extraer información de sitios web de forma automatizada. El cual implica grados de creatividad para poder realizar de forma exitosa la extracción de datos, puesto siempre varia.
Para nuestro nuestro caso, se extrae información de un sitio web estático, es decir, el código esta disponible de manera inmediata para extraer.
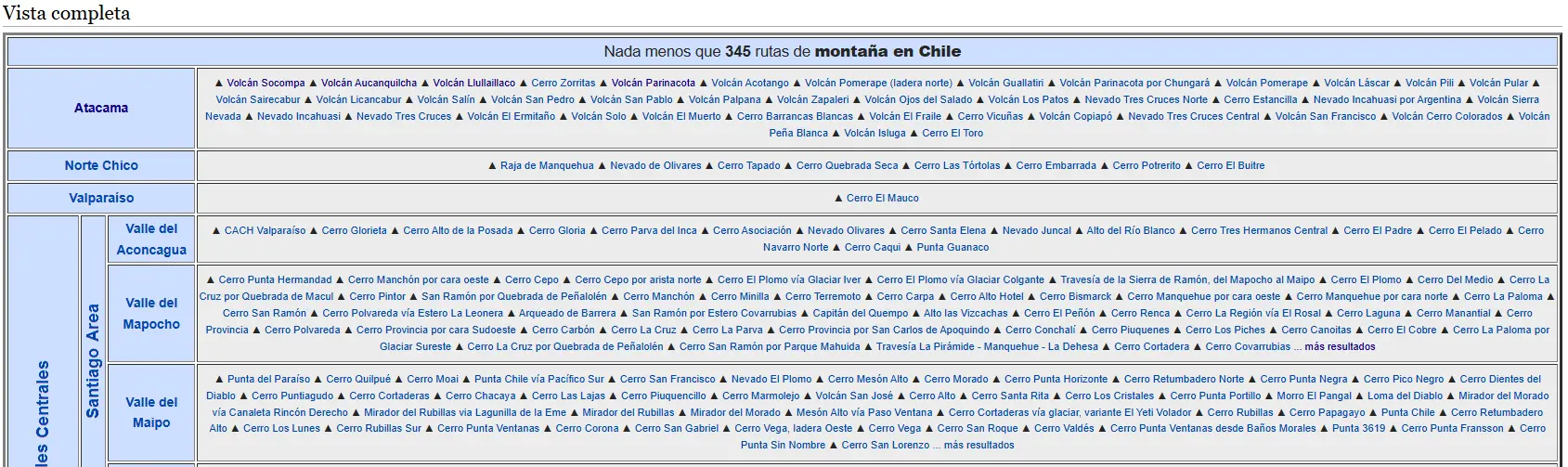
Nuestra meta es extraer todos los datos disponible de https://www.wikiexplora.com/Monta%C3%B1a_Chile de la tabla, el cual nos brinda el enlace de cada una de las montañas de Chile, y sus respectivas dificultades, altura, etc.
- Como el código esta disponible utilizamos
BeautifulSoupen Python para extraer toda la información disponible. - Para extraer las urls
BeautifulSouptiene la siguiente función:
1
2
3
4
5
data = []
for link in soup.find_all('a'):
data.append(str(link.get('href')))
El cual nos brinda 741 resultados, por lo tanto debemos utilizar nuestra creatividad para obtener los resultados deseados. En mi caso utilicé 5 filtros para llegar al resultado final con el primero:
1
2
3
4
5
6
7
filtro_1 = []
for word in data:
if word.startswith('/'):
filtro_1.append(word)
Esto es porque nuestra información se encuentra con el carácter / anterior, ejemplo '/Cerro_Zorritas' El segundo filtro es saber la posición de /Cerro_Douglas que es el ultimo cerro de la lista.
 El cual corresponde la posición 320, pero como Python inicia del 0 corresponde a la posición real 321
El cual corresponde la posición 320, pero como Python inicia del 0 corresponde a la posición real 321
1
filtro_2 = filtro_1[0:321]
El tercer filtro, como vemos la columna que contiene el origen de la zona donde son las montañas reciben el nombre de /Trekking vamos a filtrar aquellos datos para obtener solo las montañas.
1
2
3
4
5
6
7
8
9
filtro_3 = []
for word in filtro_2:
if word.startswith('/Trekking'):
filtro_3.append(word)
filtro_4 = [e for e in filtro_2 if e not in filtro_3]
El ultimo filtro es para los casos especiales que tienen el nombre /Especial y se limpia como vimos anteriormente.
1
2
3
4
5
6
7
8
9
filtro_5 = []
for word in filtro_4:
if word.startswith('/Especial'):
filtro_5.append(word)
filtro_final = [e for e in filtro_4 if e not in filtro_5]
Finalmente obtenemos 289, y si se preguntan porque si bien dice que son 345, obtuvimos estos datos, la razón es simple, no todos se encuentra de manera disponible en la pagina principal  Pero a lo que vinimos, extraer la data. Creamos una pseduofunción para comprobar que funciona
Pero a lo que vinimos, extraer la data. Creamos una pseduofunción para comprobar que funciona
1
2
3
link = 'https://www.wikiexplora.com'
link + filtro_final[0]
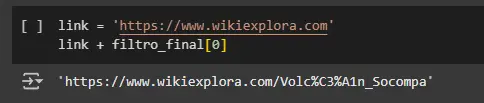
Y listo!
Tenemos listo nuestra lista para acceder a los enlaces y extraer la información, reciclamos el código anterior del GITHUB, para crear una función que extraiga todo los datos
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
for idx, nombre in enumerate(filtro_final[:100]):
url = link + nombre
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
tabla = soup.find('table', class_="infobox")
if tabla:
header = []
rows = []
for i, row in enumerate(tabla.find_all('tr')):
if i == 0:
header = [el.text.strip() for el in row.find_all('th')]
else:
rows.append([el.text.strip() for el in row.find_all('td')])
flat_list = [item for sublist in rows for item in sublist]
flat_list = [x for x in flat_list if x != '']
flat_list = [s.replace('\xa0', ' ') for s in flat_list]
flat_list = flat_list[:13]
flat_list.append(nombre)
df.loc[idx, :] = flat_list
Comprobamos… 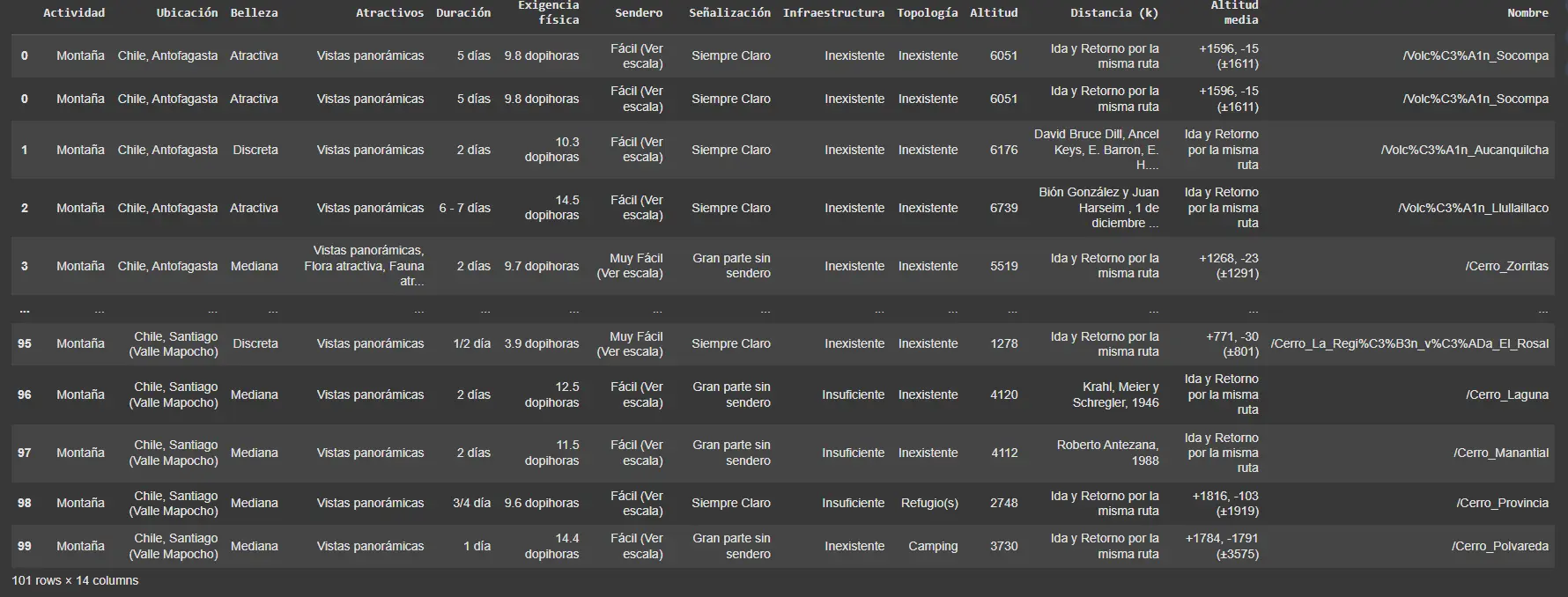 Lo logramos, creamos una manera mas eficiente y rápida de extracción de datos que la primera vez con
Lo logramos, creamos una manera mas eficiente y rápida de extracción de datos que la primera vez con BeautifulSoup, en vez de utilizar 32 datos, ahora son 289!
Recordemos los detalles, podemos utilizar este paquete porque el sitio web es estático el cual nos brinda toda la información en el código. Afrontamos el problema filtrando toda la sopa de código de manera creativa para obtener los links compatibles y finalmente extraemos la preciada información.