Ingeniería Inversa API

Ingeniería inversa API
Vamos a ver una aplicación sencilla de ingeniería inversa en un problema real para poder obtener la información del sitio web.
Para nuestra aventura utilizaremos la siguiente pagina: https://www.liquidos.cl/categorias/despacho-gratis
Si intentamos obtener la información de la forma clásica de web scraping, no podremos obtener los datos puesto es una sitio dinámico, no carga toda su información al instante como seria en un caso perfecto de forma estática.
Es por esto que debemos ver la información del back end del sitio y comprender como funciona.
Entonces hacemos los siguientes pasos:
Inspeccionar elementos con nuestro browser de preferencia
Dirigirse a
Networkpara ver que elementos son llamados
Seleccionar el filtro de
Fetch/XHR
Observar que
APIesta siendo llamada cuando ingresamos al sitio, es una buen ejercicio volver a cargar el sitio para ver el orden.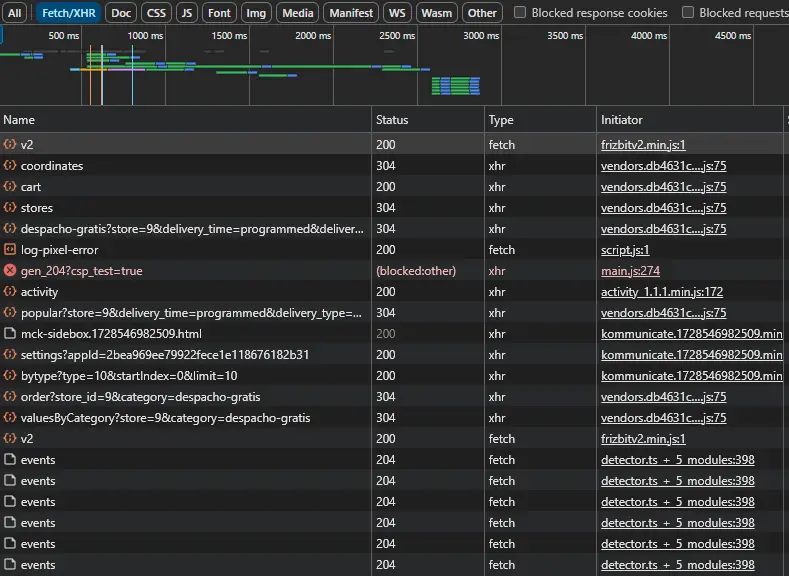
Ingresamos a cada link hasta encontrar la información deseada

Una vez ingresado a link correcto observaremos un ladrillo de texto, podemos cerciorarse que corresponde al correcto buscando con
Crt + flos términos deseados. Si utilizamos el navegadorbravepodemos utilizar su funciónpretty printpara que sea mas amigable a la vista.
Existen 2 formas de traer estos datos, la primera y mas usada es mediante la función curl llamar el link del la API con la información. La otra forma que es la que vamos a utilizar es descargar la información del API y de esta manera dejar registro atemporal y reproducible.
Manos a la obra
Tenemos nuestro archivo liquidos.JSON que generemos gracias al API, sabemos que es JSON por su forma:
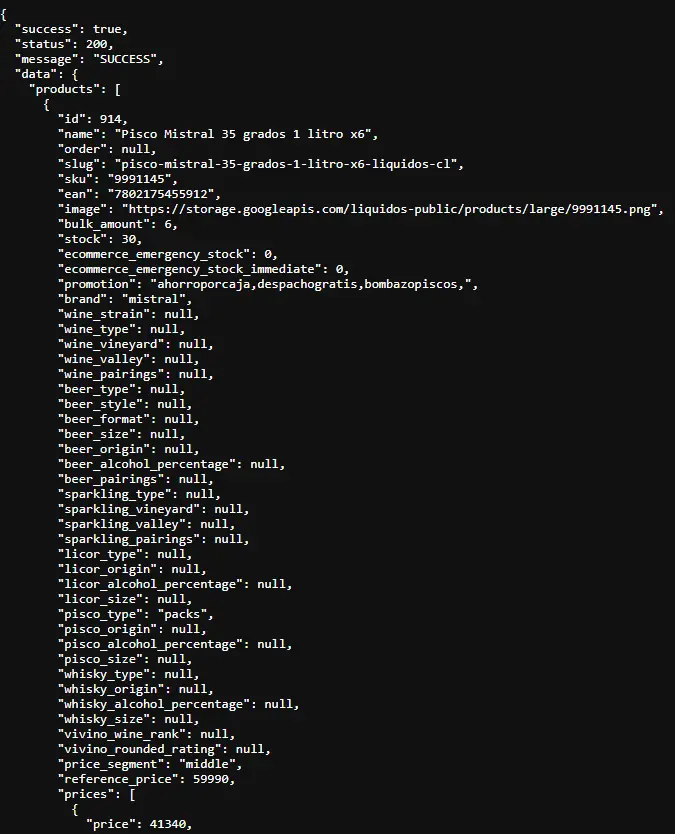
Mi herramienta favorita para este tipo de actividades es Python , como sabemos que vamos a trabajar con un json importamos su librería. Vamos a ver el script por partes para entender como funciona
1
2
3
4
5
import json
with open('Liquidos.json') as json_file:
data = json.load(json_file)
con la función with open podemos abrir un archivo local, en nuestro caso lo convertimos a un json_file, entonces cargamos los datos con la variable data que llame la función json.load que carga archivos .json para nuestra manipulación de datos.
1
2
print(data['data']['products'][0]['name'])
print(data['data']['products'][0]['prices'][0]['price'])
Con los print descubrimos la ruta del archivo que llama las variables que nosotros queremos recolectar, en nuestro caso es el nombre y su precio.
Nuestra raíz data['data']['products'][x] nos entrega toda la información de los 17 elementos que deseamos y con esta podemos definir un ciclo para extraer toda la información.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
lista_productos = []
with open('Liquidos.json') as json_file:
data = json.load(json_file)
nombre = []
precio = []
for x in range(17):
nombre = (data['data']['products'][x]['name'])
precio =(data['data']['products'][x]['prices'][0]['price'])
producto = {
'Producto': nombre,
'Precio': precio
}
lista_productos.append(producto)
Nos entrega una lista con los productos que deseamos de una forma amigable la vista, si deseamos generar un dataframe véase el código en GITHUB.
Entonces en el post aprendimos como realizar Ingeniería inversa para un caso real extracción de datos, una manera mas sencilla y amigable para entender como funciona .json, y escribir un script en Python para unir toda la aventura. Recordemos que para nuestras aventuras de web scraping van a variar según lo que enfrentemos, pero espero querido lector que estés cada vez mas cerca de conseguirlo.