Caso real

Caso Real
El siguiente caso corresponde a una prueba técnica para una entrevista laboral la cual buscaba técnicas de transformación de datos, unir archivos, crear una lista con toda la información necesaria, al igual que finalmente crear una función estadística, en mi caso voy a utilizar R porque es mi herramienta favorita

Primer paso
Lo primero que tenemos que saber es donde se encuentra el ambiente de trabajo, para esto utilizamos la función getwd , lo que es pwd en Linux, para nosotros escoger la dirección de trabajo se utiliza la función setwd.
Otra arista que tenemos que hacer antes de trabajar con los datos es descomprimir los archivos con los que vamos a trabajar y guardarlos en la dirección que pusimos anteriormente. Como los archivos tienen un formato xlxs la cual se utiliza para archivos Excel, para trabajar con este archivo en R utilizamos un paquete llamado readxl, luego utilizamos otra función de base R para poder leer múltiples archivos con file.list y finalmente utilizamos lapply para generar una lista con todos los archivos en conjunto.
Para entender lo que hicimos veamos el siguiente orden cronológico
- Ver el ambiente de trabajo con
getwdsi no es que queremos lo cambiamos consetwd - Descomprimir los archivos que nos entrega el formato
xlxs - Utilizar
readxlpara leer el formatoxlxs - Leer todos los archivos con
file.listy crear una lista con todos estos conlapply
Segundo paso
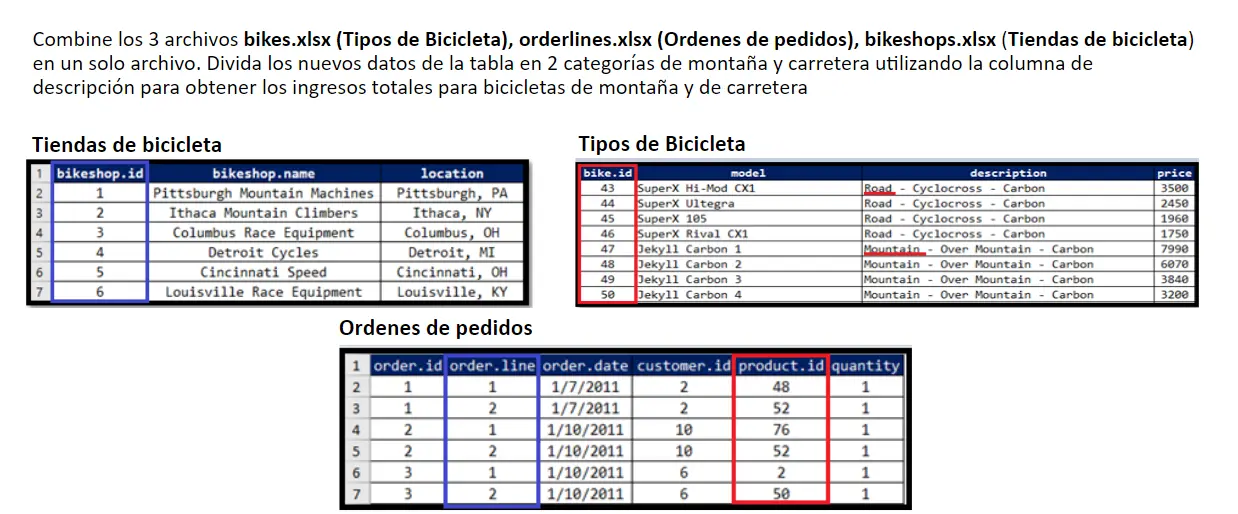
Se nos pide unir las tablas, las columnas rojas con las rojas y las azules. Para nuestra ayuda podemos utilizar la función left_join para unir las tablas, para los conocedores de SQL hace lo mismo pero en nuestro software R.
Ahora también se nos pide modificar los datos, en especifico quitar la primera palabra de la descripción para crear su propia categoría y saber si la bicicleta es de carretera o montaña. Para esto utilizamos la función word que para nuestro beneficio corta la primera palabra.
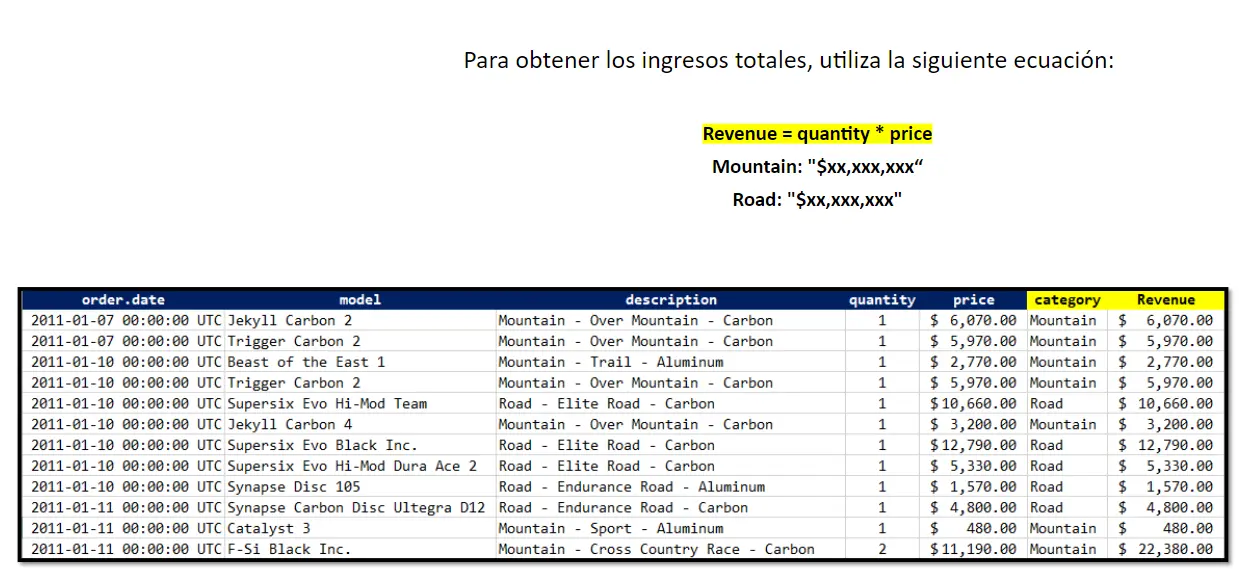
Nos pide crear otra columna que se llame Revenue que es muy fácil Revenue completo$quantity * completo$price y listo!
Tercer paso
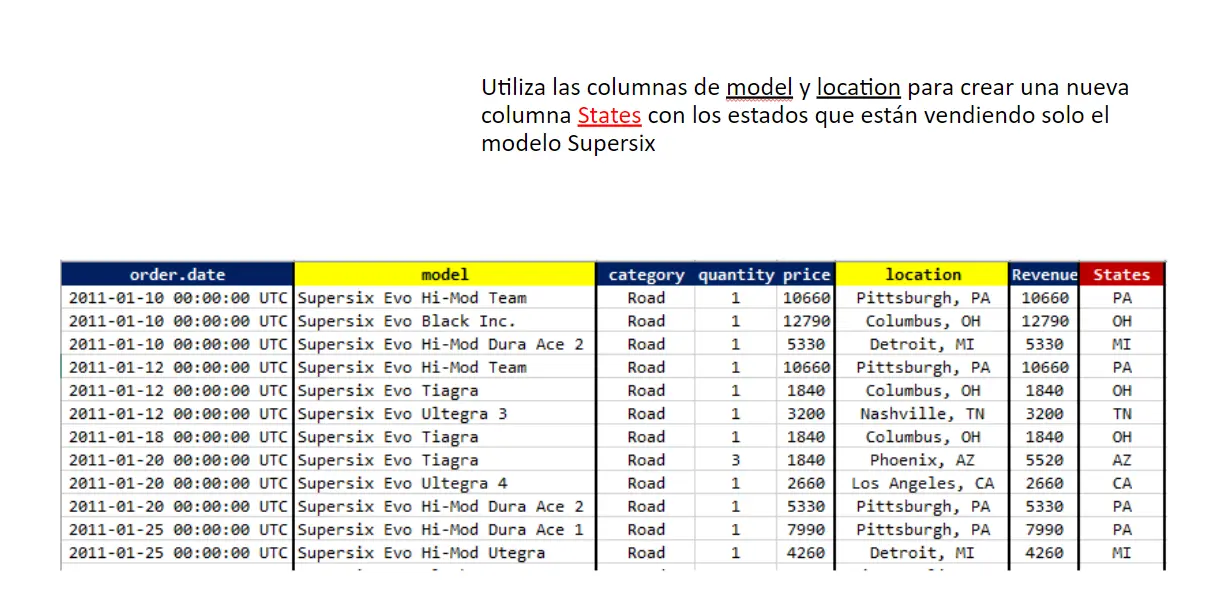
Subset nueva variable y agregar estados. En este caso es muy sencillo filtrar el modelo Supersix utilizamos la función filter y str_detect. Para poder separar el estado de la columna location utilizamos str_sub de esta manera tenemos los estados!
Ultimo paso
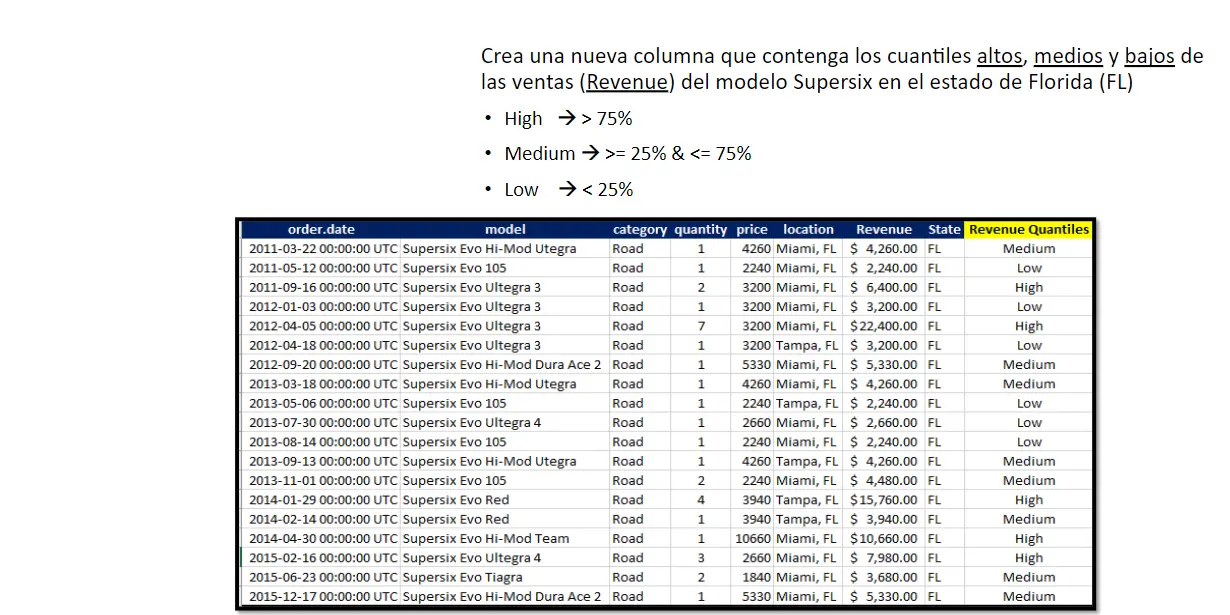
Como aprendimos anteriormente para filtrar utilizamos filter(str_detect()), nuestro caso es FL.
Finalmente tenemos que crear una función que vea 3 estados posibles de las ventas, como conocimiento estadístico conocemos este concepto como cuartil el primer cuantil 1 corresponde a la sumatoria hasta el 25%, el segundo cuartil al siguiente 25% es decir, que corresponde justo al 50% y el tercer cuartil corresponde a 75%.
Que quiero decir con todo esto, pues que la regla que se nos impone es correspondiente con el cuartil es por esto mismo que para tener la función con los valores correctos utilizamos la función quantile para saber los valores.
Creamos finalmente la siguiente función
1
2
3
4
5
6
7
8
9
10
11
for (i in 1:19){
if(Supersix_FL$Revenue[i] > 5865){
RQ[i] <- 'High'
}else
if((Supersix_FL$Revenue[i] <= 5865) & (Supersix_FL$Revenue[i] >= 3200)){
RQ[i] <- 'Medium'
}else
if(Supersix_FL$Revenue[i] < 3200){
RQ[i] <- 'Low'
}
}
Así podemos responder cuantos valores son bajos, medios o altos. Para que usted pueda entender mejor el código se encuentra en GITHUB.
Finalmente la mejor forma de aprender es metiendo las manos al barro y romper las cosas para saber como funcionan, espero querido lector que encuentre lo que esta buscando, tengo otros proyectos de ciencia de datos en mi perfil de GITHUB cuales implican web scraping, visión artificial y Deep Learning utilizando Python.