Análisis de datos python

Ciencia de datos

La ciencia de datos es una disciplina que mediante la combinación de modelos matemáticos y estadísticos, la programación computacional y las técnicas de visualización de datos, te permitirán obtener el máximo valor de los datos para apoyar los procesos de toma de decisiones.
En este caso el análisis es sobre el set de datos MAGIC sobre partículas de alta energía. Lo importante en este caso es como un Data scientist trabaja, por eso vamos a comparar primero las densidades de las variables para entender en que se diferencian, transformar los datos para nuestra utilidad y finalmente poder utilizar modelos de predicción machine learning y ver como se ajustan al set.
Podemos observar, gracias al histograma existen diferentes comportamientos en las columnas:
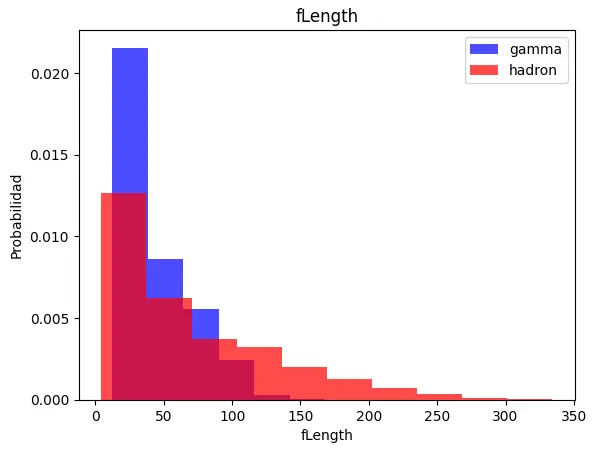
- fLength donde gamma tiene un comportamiento más alto. fAsym gamma tiene un comportamiento más alto.
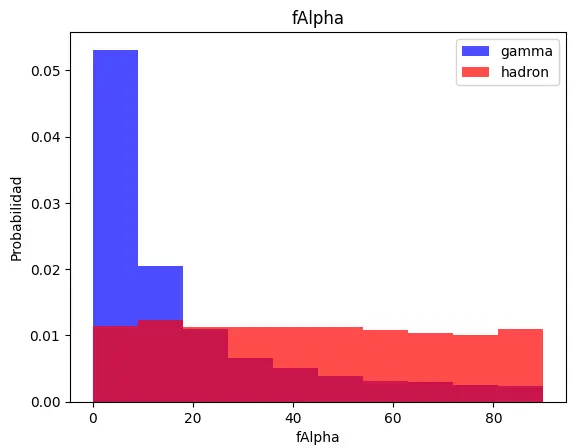
fAlpha gamma tiene una distribución exponencial, mientras que hadron tiene una distribución mas uniforme.
Mientras las demás tiene comportamientos más similares entre sí.
El set de datos tiene valores que tiene mucha diferencia el uno con el otro, es por esto que se crea una función que escala los datos, la función utiliza la estandarización, es decir, restar su promedio y dividir por su desviación estándar.
Encontramos que existe una diferencias entre los valores de Gamma y Hadron que pueden generar problemas al querer utilizar modelos de predicción, puesto que se puede sobreponer los valores. Es por esto que es necesario generar una nueva muestra más proporcional entre sí.
Modelos predictivos
Existen diferentes tipos de modelos predictivos en ML, en nuestro ejemplo solo utilizaremos modelos supervisados, lo que quiere decir, que aprende la relación entre la entrada y la salida.
KNN - Metodo de k vecino más cercano -
En este metodo evaluamos que a medida que tenemos más n vecinos tenemos mejores resultados.
Bayesiano ingenuo
El modelo no parece ajustarse de la mejor manera para entregarnos los mejores resultados.
Regresión logística
El modelo nos entrega mejor resultados mejores que Bayes, pero no KNN.
Maquina de vectores de soporte
Con este modelo tenemos el mejor resultado con todos los métodos anteriores.
Redes neuronales
Obtenemos los mejores resultados.
Si bien el modelo más complejo ofrece los mejores resultados, su tiempo de procesamiento es considerable. Por lo tanto, la eleccion del modelo ideal dependerá de un cuidadoso análisis del contexto y de las restricciones de tiempo que tengamos. Vease GITHUB para el codigo y mayor desarrollo.